Table of contents |
| Systems of complex behavior |
| Software design and maintainability issues |
| Data management aspect |
| Business process aspect |
The goal of this project is to investigate data management for systems of complex behavior. Before going on data management issues it is necessary to define what the complex behavior is. Webster vocabulary says:
Complex Com"plex, a. L. complexus, p. p. of complecti to
entwine around, comprise; com- + plectere to twist,
akin to plicare to fold.
Composed of two or more parts; composite;
not simple; as, a complex being; a complex idea.
Ideas thus made up of several simple ones put
together, I call complex; such as beauty, gratitude,
a man, an army, the universe. --Locke.
|
From this citing complex behavior can be determinate as a behavior consisting of two or more simple reactions following one another or a reaction chosen depending upon either environment or inner system state. In other words, behavior is a reaction to an event. Complex behavior is reaction that is rather strategy than action. There is no strict line of demarcation between these two reaction types. Strategy is also can be simple however there is important point - strategy being built involving inner system state whereas a simple reaction doesn't require one.
Any software application can be considered as system of complex behavior if this application evolves (business logic becomes more complex) and this application handles multiple data streams.
Usually any program (even very simple one) is aimed to process data. This can be calculations, user interaction or networking. The big difference is where this information comes from or being sent to. Until an application uses a backend components such as a database and a relatively simple user interface (UI) to input data this application still may be a relatively simple. The maintenance cost will be directly equal to software quality (if this works well and users don't waste time for restarting or restoring lost data). However as soon as execution requirements getting more complex this tends to change. Data comes from multiple sources, number of users may increase significantly, amount of processing data getting huge. Under such circumstances all design flaws increase maintenance cost by many times. To make a system that perfectly survies under such circumstances during reasonable time takes plentiful efforts:
Consider an example:
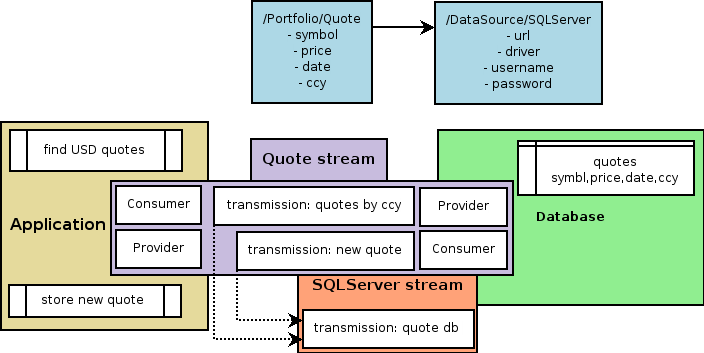
There is an entity named Quote in context of portfolio management. The range of possible data
transmissions implies Quote stream. The Quote transmissions may be as different as business logic
demands. Let's consider finding a quote by currency and storing new quote.
Data model management begins with creating a database. The database for this little example
will contain a table:
quotes |
| symbol |
| price |
| date |
| ccy |
This stage is absolutely the same for describing concept with the difference that the database may already exist or this may be not a database at all. So that we assume that this database will be treated as a part of quote stream. Evidently, hypothetical application will be the counterpart for some transmissions of this stream. Realizing this arises a question whether the application shall know what the data source is? The answer is no. The application relies on the stream metadata (entity Quote is the metadata of this stream) and absolutely doesn't need to know where the data comes from unless application needs to manage quality of this transmission.
The next stage is to ensure application is able to access the data properly. This includes setting up credentials for data access, validating correspondence between object and relational models. All of that depends on chosen persistence management level. J2EE application may rely on J2EE Connector Architecture to get major part of this done however a small or in-house application probably would require some additional efforts. With AADMS this is part of stream planning. Each data transmission within a stream can be based on another data transmission of another stream. For the example there will be added one more entity called SQLServer in context of DataSource. This entity is introduced just to specify the access to the database. Developer may associate with this entity a procedure obtaining a password or anything else however link between Quote and SQLServer should not change.
The picture above illustrates this dependency. Transmission quote by ccy performs sql query to find quotes however this sql statement must be sent to appropriate datasource. AADMS will resolve this reference and send this sql statement to the database identified by DataSource/SQLServer/quote db transmission. The meaning of quote db is following: by means of this transmission client (in this case inner AADMS procedure, responsible for executing a query) obtains a connection to the database. As it seen from the picture SQLServer defines attributes to access the resource. When AADMS starts there is a phase when it initializes resources. Initialization here may mean everything: from getting a connection off the pool till asking a user to input username and password. It depends on handler specified for quote db transmission.
Data consistency and validation rules usually are part of business logic. Using one of available OR mapping systems (Hibernate, JDO flavor, etc) reduces coding by means OR model created for the application. AADMS may reuse OR model to monitor data streams between persistence storage and application. AADMS's nature let monitor or manage any data stream available. This includes validation and consistency checks. Since AADMS model consists of meta objects (entities) that describe stream metadata and AADMS manages data delivery it may check what comes in and out. AADMS understands data transmission as sequence of transaction events and is able to trigger an action on certain events. To achieve that AADMS being shipped with Rule Based engine inside.
Finally, data is lifted up to the business logic level and validated. According to business logic rules the application performs data processing which may involve additional protocols such as mail, xml serialization, etc. Average application uses various APIs to fulfill these tasks using adapters for 3rd party components and does many other things. Now let's try to look at this from stream prospective. Sending a mail is still the same data stream where application is start point and recipient is the end. AADMS doesn't differentiate if this mail delivery or sql query. AADMS uses stream notion for sending mails or SOAP messages. Instead of multiple APIs the application relies solely on AADMS to handle all data delivery tasks.
Transmission new quote shown on the picture alike quote by ccy accesses SQL server to save added quote. However, in this case the application becomes a start point for this data transmission and SQL handler, which represents the database, is its end. The same as with the first transmission the application doesn't care where the data comes to. With AADMS it is rather configuration issue than programming task. The snippet below demonstrates how to save created quote in java pseudo code:
Code listing |
MetaModel mm = ModelFactory.getMetaModel( );
// Get domain which the stream belongs to
Domain portfolio = mm.getDomain("Portfolio");
// Get stream to run
Stream newQuoteStream = portfolio.getStream("Quote/new quote");
// Create new quote
Quote msftQuote = new Quote("MSFT",120.0,"USD");
// Prepare stream to deliver the data
newQuoteStream.transmit(msftQuote);
// Perform transmission
newQuoteStream.run ( );
|
According to this snippet, the current execution step of application requests a quote stream by name. Save quote logic is decoupled from application code what makes it clean and readable. Readable syntax let describe business logic using scripting languages like Java BeanShell, [CJ]Python, etc. AADMS hides all difficulties and allow configure default behavior when exception occurs. Despite that developer is able to control each step of data transmission. It means that application still may interact with AADMS while execution.